How does Raysync enable online decompression of multiple compressed file types?
April 12, 2024In daily file storage, many compressed files are transferred to file servers, such as commonly used zip, 7zip, tar formats. Users are unable to view or preview compressed files on the server. The ability to decompress files online on the server can solve this issue and significantly improve customer experience in various aspects. For example, web-based online decompression allows customers to directly unzip files in their browser without installing any decompression software on their computers. They can download specific files without downloading the entire compressed file, reducing unnecessary transfer time. Additionally, customers can browse the decompressed files, which is convenient for users who do not want to download files locally.
Raysync achieves online support for decompressing multiple formats, including popular compression formats such as tar, 7zip, zip, rar, by integrating the powerful libarchive program library.
Part 1: What is Libarchive
Libarchive is a powerful and highly portable C library specifically designed for handling various archive files. It supports various common archive formats such as tar, zip, 7zip, and ISO images.
Key features of Libarchive:
Rich functionality: Libarchive provides functions for reading and writing archive files. It can be used for decompressing, compressing, encrypting, and signing files.
Cross-platform support: Due to its high portability, Libarchive can run on different operating systems, including Windows, Linux, and Mac.
Wide application: Libarchive is widely used in various applications, including prominent operating systems such as Windows 10 and macOS. It is a powerful and flexible tool for handling various archive formats.
Ongoing maintenance: The open-source Libarchive community is active and well-maintained, ensuring prompt issue resolution and updates.
High performance: Libarchive's internal IO model is designed with zero-copy design, minimizing data copying for optimal performance, especially when dealing with large archive files.
Part 2: Integrating Libarchive
Compilation:
Obtain the open-source code from GitHub (https://github.com/libarchive/libarchive).
Read the Readme.md document in the project for compilation and understand the support of CMakeLists.txt.
Use CMake GUI to configure CMakeLists.txt as a VS project. During the conversion, some dependencies need to be configured.
Compression algorithm dependency libraries: LZ4, LZO, LZMA, Zstandard, Bzip2.
Encryption dependency libraries: Mbed TLS, GNU Nettle, OpenSSL.
Add the corresponding dependency libraries according to your needs. For example, add ZLIB for zip and LZMA for 7zip. In the configuration shown in the figure, ZLIB is configured. The configuration process for other libraries is the same. Alternatively, during the dependency library compilation, you can directly use "make install" for installation. This will automatically find the corresponding libraries during CMake configuration.
After generating the VS project, compile and generate dynamic and static libraries. If you need static linking, add the macro definition LZMA_API_STATIC to the header file <archive.h>. If you need to support lower-version environments below Windows 8, set WIN32_WINNT and WINVER to the value of the low-version environment in <config.h>, as shown in the figure for Windows 7.
Code integration:
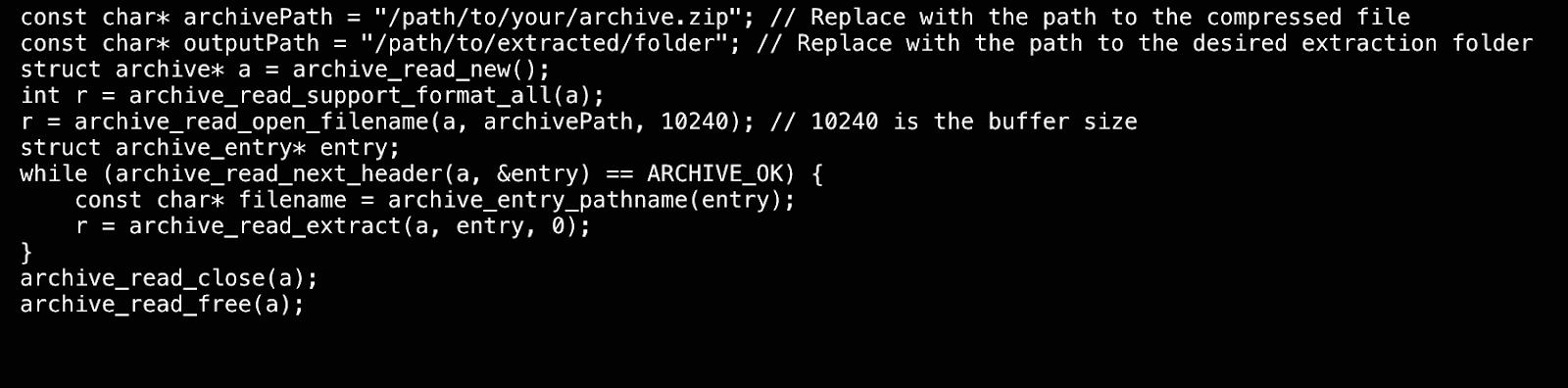
Using Libarchive requires basic objects of struct archive and struct archive_entry. struct archive represents the instance of the original compressed file, and struct archive_entry represents the instance of a file within the compressed file. The rough calling process in Libarchive is as follows:
Call archive_xxx_new to create an archive object.
Call support or set to configure properties and check if the archive object supports the decompression format.
Call open to open the compressed file.
Loop to read the archive contents: Get a new archive_entry and extract compressed file data from archive_entry.
At the end, use close and free to release the archive object.
Below is a simple example:
Note:
If you encounter issues with retrieving the file name as empty or garbled, you can resolve it by:
Call ::setlocale(LC_CTYPE, "") to set the default character environment of the program.
Use archive_entry_pathname_w and archive_entry_pathname_utf8 instead of archive_entry_pathname.
When the character encoding of the compressed file is not properly set, such as multiple character encodings, resulting in garbled file names, you need to determine the character encoding, usually UTF-8 or GBK.
Decompressing files is a high-resource consuming action on the server, so it is necessary to impose limitations on the reading speed, timely release of threads, memory, and other resources in the decompression functionality to prevent impacting the normal operation of the server.
Conclusion
By following the aforementioned steps, Raysync has achieved online decompression functionality on Windows, Linux, and other platforms. This provides enterprises with a robust and secure file transfer system with an online decompression feature. It not only meets the diverse data processing needs in various scenarios but also provides long-term technical support for enterprise development. Raysync will continue to play a vital role in the field of file transfer, helping enterprises achieve more efficient and intelligent data management.
You might also like

Raysync News
March 28, 2024Raysync V6.8.8.0 is updated and upgraded with the latest version!

Raysync News
January 18, 2024In this article, we will explore two common file transfer protocols: FTP and TCP, analyze their efficiencies, and propose how Raysync technology can improve file transfer efficiency.
Raysync News
June 17, 2022This article details several file sync methods for Window 11, how to choose the most effective file sync method? Click to learn more!